Redis
-
[Redis] Windows 에 Redis 설치하기2023.05.29
-
[Redis] 레디스 데이터 타입 - Geospatial2023.02.03
-
[Redis] 레디스 데이터 타입 - Sorted Set2023.01.30
-
[Redis] 레디스 데이터 타입 - Hash2023.01.25
-
[Redis] 레디스 데이터 타입 - Set2023.01.23
-
[Redis] 레디스 데이터 타입 - List2023.01.20
[Redis] Windows 에 Redis 설치하기

| 들어가며 |
Redis 를 UNIX 기반의 OS에 설치 하지만, 테스트 및 개발환경이 Windows 라면, 임시적으로 사용하기 편한게 Windows Redis 인데요. 최신버전이 아니라는 단점이 있지만, 기본적인 테스트 용도로는 적절하게 사용 가능 할 것 같아서 정리하였습니다.
| ## 다운로드 |
https://github.com/microsoftarchive/redis/releases
Releases · microsoftarchive/redis
Redis is an in-memory database that persists on disk. The data model is key-value, but many different kind of values are supported: Strings, Lists, Sets, Sorted Sets, Hashes - microsoftarchive/redis
github.com
Last 버전이 3.0.504 버전이라는 점은 꼭, 설치전 확인해주세요
현재 7.0 버전까지 나왔으니까요..
| ## 설치 |
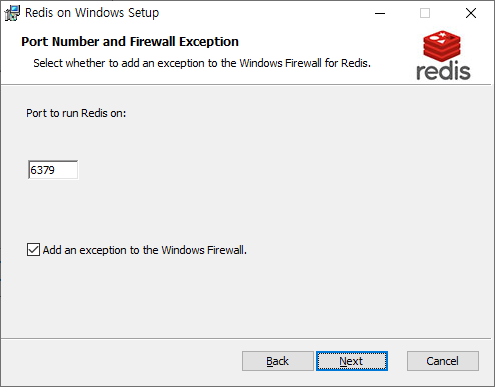
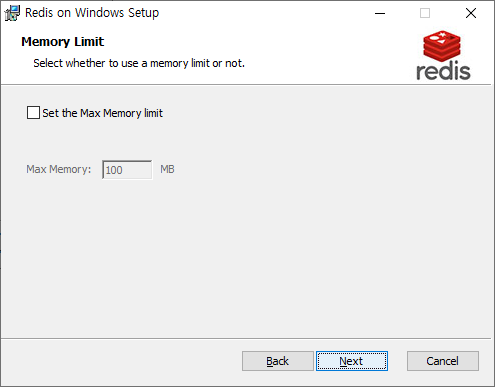
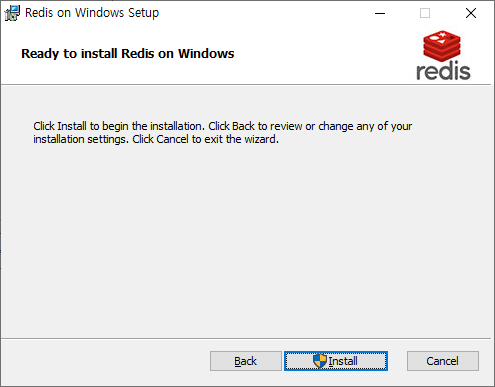
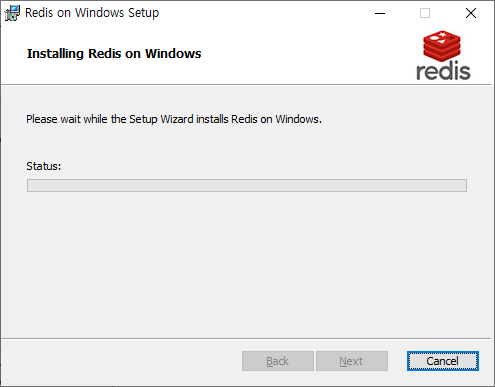
설치하는 방법은 크게 어렵지 않습니다. 기본적인 포트 및 메모리 설치 위치 정도 설정해주면 되며, 중간에 환경변수 등록도 체크해주시면 됩니다.
설치 완료시 Service에 등록되니 바로 사용 하 실 수 있습니다.
| ## redis-cli |
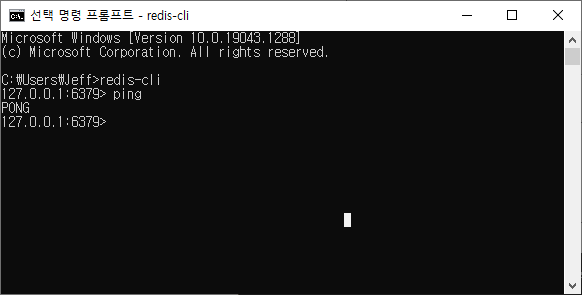
CMD 창을 이용해서, redis-cli 를 실행시킨 후, ping을 때리니 정상적으로 "PONG" 응답이 오네요!!
가볍게 테스트 용도에서의 레디스로 사용하긴 편리합니다.
| 참조 |
END
'Redis' 카테고리의 다른 글
| [Redis] 레디스 데이터 타입 - Geospatial (0) | 2023.02.03 |
|---|---|
| [Redis] 레디스 데이터 타입 - Sorted Set (0) | 2023.01.30 |
| [Redis] 레디스 데이터 타입 - Hash (0) | 2023.01.25 |
| [Redis] 레디스 데이터 타입 - Set (0) | 2023.01.23 |
| [Redis] 레디스 데이터 타입 - List (0) | 2023.01.20 |
[Redis] 레디스 데이터 타입 - Geospatial

Geospatial
- Geospatial 인덱스를 사용하면 좌표를 저장하고 검색 할 수 있다.
- 이 데이터 구조는 주어진 반경 또는 경계상자 내에서 가까운 지점을 찾는데 유용하다.
기본 명령어
-- 지리공간 인덱스 위치를 추가한다 (경도, 위도)
GEOADD <key> <longitude> <latitude> <member>
-- geospatial 인덱스에서 두 맴버간 거리를 반환한다. unit : [m, km, pt, mi]
GEODIST <key> <member1> <member2> <unit>
-- 지정된 반경 또는 경계상자가 있는 위치를 반환 (6.2 이후)
GEOSEARCH <key> <startscore> <endscore>
참조
https://redis.io/docs/data-types/geospatial/
https://redis.io/commands/?group=geo
END
'Redis' 카테고리의 다른 글
| [Redis] Windows 에 Redis 설치하기 (0) | 2023.05.29 |
|---|---|
| [Redis] 레디스 데이터 타입 - Sorted Set (0) | 2023.01.30 |
| [Redis] 레디스 데이터 타입 - Hash (0) | 2023.01.25 |
| [Redis] 레디스 데이터 타입 - Set (0) | 2023.01.23 |
| [Redis] 레디스 데이터 타입 - List (0) | 2023.01.20 |
[Redis] 레디스 데이터 타입 - Sorted Set

Sorted Set
- 연관된 점수로 정렬된 고유한 문자열의 모음이다.
- Set과 동일하게 Key 하나에 중복되지 않는 여러 맴버를 저장하지만, 각각의 맴버는 Score 에 연결된다.
- 모든 데이터는 Score 값으로 정렬되며, Score가 같다면 문자열의 사전 순서로 정렬된다.
- 정렬이 필요한 곳에 사용되며, 주로 Rank를 생성할때 이용한다.
- Score는 double 이기 때문에 부동 소수점에 주의 해야 한다.
기본 명령어
--이미 value 가 있다면 score 값만 변경한다.
ZADD <key> <score> <value>
-- 해당 index 범위의 모든 value를 반환한다. 0, -1 일경우 전체
ZRANGE <key> <startindex> <endindex>
-- 해당 Score 범위의 모든 값을 반환, endsocre가 +inf 일 경우 끝까지
ZRANGEBYSCORE <key> <startscore> <endscore>
-- 오름차순 기준의 맴버 순위 제공 (index 0 부터)
ZRANK <key> <member>
-- 내림차순 기준의 맴버 순위 제공 (index 0 부터)
ZREVRANK <key> <member>
성능
대부분의 정렬된 집합 연산은 O(log(n))이며 여기서 n 은 구성원 수입니다.
ZRANGE큰 반환 값(예: 수만 이상)으로 명령을 실행할 때는 주의를 기울여야 합니다. 이 명령의 시간 복잡도는 O(log(n) + m)입니다. 여기서 m 은 반환된 결과의 수입니다.
참조
https://redis.io/docs/data-types/sorted-sets/
https://redis.io/commands/?group=sorted-set
END
'Redis' 카테고리의 다른 글
| [Redis] Windows 에 Redis 설치하기 (0) | 2023.05.29 |
|---|---|
| [Redis] 레디스 데이터 타입 - Geospatial (0) | 2023.02.03 |
| [Redis] 레디스 데이터 타입 - Hash (0) | 2023.01.25 |
| [Redis] 레디스 데이터 타입 - Set (0) | 2023.01.23 |
| [Redis] 레디스 데이터 타입 - List (0) | 2023.01.20 |
[Redis] 레디스 데이터 타입 - Hash

Hash
- field-value 쌍의 컬렉션으로 구성된 레코드 유형입니다.
- 해시를 사용하여 기본 개체를 나타내고, 카운터 그룹을 저장할 수 있습니다.
- key 에 대한 field 의 개수에는 제한이 없으므로, 여러 방법으로 사용이 가능합니다.
기본 명령어
-- 주어진 필드의 값을 반환한다.
HGET <key> <field>
HMGET <key> <field1> <field2>
-- 해시에서 하나 이상의 필드값을 설정한다.
HSET <key> <field> <value>
MHSET <key> <field1> <value1> <field2> <value2>
-- 해당 key의 모든 field value 조회
HGETALL <key>
-- 주어진 필드의 값을 제공된 value 만큼 증가시킨다.
HINCRBY <key> <field> <value>
성능 및 제한
대부분의 Redis 해시 명령은 O(1)입니다.
HKEYS, HVALS및 - 와 같은 몇 가지 명령 HGETALL은 O(n)이며 여기서 n 은 필드-값 쌍의 수입니다.
모든 해시는 최대 4,294,967,295(2^32 - 1) 필드-값 쌍을 저장할 수 있습니다. 실제로 해시는 Redis 배포를 호스팅하는 VM의 전체 메모리에 의해서만 제한됩니다.
참조
https://redis.io/commands/?group=hash
END
'Redis' 카테고리의 다른 글
| [Redis] 레디스 데이터 타입 - Geospatial (0) | 2023.02.03 |
|---|---|
| [Redis] 레디스 데이터 타입 - Sorted Set (0) | 2023.01.30 |
| [Redis] 레디스 데이터 타입 - Set (0) | 2023.01.23 |
| [Redis] 레디스 데이터 타입 - List (0) | 2023.01.20 |
| [Redis] 레디스 데이터 타입 - String (0) | 2023.01.18 |
[Redis] 레디스 데이터 타입 - Set

Set
- 아이템이 중복되지 않고, 정렬되지 않은 문자열의 모음입니다.
- 고유한 항목을 추적합니다.
- 교집합, 합집합, 차집합 연산을 레디스에서 수행 할 수 있기 때문에 객체 간의 관계를 표현할 때 좋습니다.
기본명령어
--이미 value 가 있다면 추가 하지 않음
SADD <key> <value1> <value2>
-- key 안에 value 삭제
SREM <key> <value>
-- 모든 value를 반환
SMEMBERS <key>
-- value 가 존재하면 1, 없으면 0
SISMEMBERS <key> <value>
-- SET의 크기를 반환
SCARD <key>
-- 두개 이상의 세트에 공통적으로 갖는 맴버를 반환
SINTER <key1> <key2>
성능
추가, 제거 및 항목이 집합 구성원인지 여부를 확인하는 등 대부분의 집합 작업은 O(1)입니다. 이것은 그들이 매우 효율적이라는 것을 의미합니다. 그러나 구성원이 수십만 명 이상인 대규모 집합의 경우 SMEMBERS명령을 실행할 때 주의해야 합니다. 이 명령은 O(n)이며 전체 집합을 단일 응답으로 반환합니다. 대안 SSCAN으로 집합의 모든 구성원을 반복적으로 검색할 수 있는 를 고려하십시오.
참조
https://redis.io/commands/?group=set
END
'Redis' 카테고리의 다른 글
| [Redis] 레디스 데이터 타입 - Sorted Set (0) | 2023.01.30 |
|---|---|
| [Redis] 레디스 데이터 타입 - Hash (0) | 2023.01.25 |
| [Redis] 레디스 데이터 타입 - List (0) | 2023.01.20 |
| [Redis] 레디스 데이터 타입 - String (0) | 2023.01.18 |
| [Redis] 레디스 Collections 알아보기 (0) | 2023.01.16 |
[Redis] 레디스 데이터 타입 - List

List
- Linked List 형태이며, Head 와 Tail 에 요소를 추가할 때 동일한 시간이 소요됩니다.
- 특정 값이나 인덱스로 데이터를 찾거나 삭제할 수 있습니다.
- List는 다음과 같은 용도로 자주 사용됩니다.
- stack, queue 를 구현합니다.
- 백드라운드 작업자 시스템을 위한 대기열 관리를 구축합니다.
- pub/sub, job queue 로 활용할 수 있습니다.
- Redis List의 최대 길이는 2^32 - 1(4,294,967,295) 입니다.
기본명령
LPUSH <key> <Element1> <Element2> : 앞쪽에 Push
RPUSH <key> <Element1> <Element2> : 뒤쪽에 Push
LPOP <key> : 앞쪽에서부터 꺼냄
RPOP <key> : 뒤쪽에서부터 꺼냄
LLEN <key> : List의 크기를 반환
LRANGE <key> <start> <end> : 범위 내에 값 확인 <end> -1 일 경우, 전체
Example
LPUSH <key> <Element1> <Element2> : 앞쪽에 Push
LPOP <Element> : 앞쪽에서부터 꺼냄
RPUSH <key> <Element1> <Element2> : 뒤쪽에 Push
RPOP <Element> : 뒤쪽에서부터 꺼냄
성능
헤드 또는 테일에 액세스하는 목록 작업은 O(1)이므로 매우 효율적입니다. 그러나 목록 내의 요소를 조작하는 명령은 일반적으로 O(n)입니다. 이러한 예에는 LINDEX, LINSERT및 가 포함 LSET됩니다. 주로 큰 목록에서 작업할 때 이러한 명령을 실행할 때 주의하십시오.
참조
https://redis.io/commands/?group=list
END
'Redis' 카테고리의 다른 글
| [Redis] 레디스 데이터 타입 - Hash (0) | 2023.01.25 |
|---|---|
| [Redis] 레디스 데이터 타입 - Set (0) | 2023.01.23 |
| [Redis] 레디스 데이터 타입 - String (0) | 2023.01.18 |
| [Redis] 레디스 Collections 알아보기 (0) | 2023.01.16 |
| [Redis] 레디스 개요 (0) | 2023.01.13 |